MLflow概述
Mlflow是用于管理端到端机器学习生命周期的开源平台。它处理三个主要功能:
- Tracking:模型参数、指标记录繁琐,Tracking可以记录模型的配置信息,并可视化展示
- Projects:模型结果难以再现,Projects通过conda重现模型所需环境、依赖,使得模型结果可以复现
- Models:开发的模型部署难,Models打包、封装模型,并提供部署
本文的编写与上一篇Kashgari一样,使用Mlflow可视化NER模型的调参以及保存和部署
本项目的全部代码见我个人的 github 项目ner_s2s中的 estimator 模式
MLflow 的 Github 网址
NER 命名实体识别
安装
- python推荐使用conda环境,可以多平台一样运行
- 本文 python 版本为 3.6, mlflow 版本为 1.3
conda create --name ner python=3.6
pip install mlflow==1.3.0
Tracking
首先引入 Tracking 所必须的库,mlflow.tensorflow.autolog()这个全局函数能够自动追踪标准的变化情况
import mlflow
import mlflow.tensorflow
# Enable auto-logging to MLflow to capture TensorBoard metrics.
mlflow.tensorflow.autolog()
下面代码展示的是如何使用Tracking功能,可以看到使用过程非常简单, 可以自由的选择
- mlflow.log_param(“key”, value) log模型参数
- ……
mlflow.log_param("Batch_Size", config["batch_size"])
mlflow.log_param("Learning_Rate", config["learning_rate"])
mlflow.log_param("Epochs", config["epochs"])
mlflow.log_param("Embedding_Dim", config["embedding_dim"])
比较模型
程序执行结束后会生成一个mlruns的文件夹,记录每次程序的信息
接下来在根目录下,使用MLflow UI比较生成的模型
mlflow ui
并在 localhost:5000中查看,这里如果 5000 端口一直被占用(比如在服务器中),可以重定向到其他端口比如:
mlflow ui -p 5001
在此页面上,我们可以看到实验运行列表
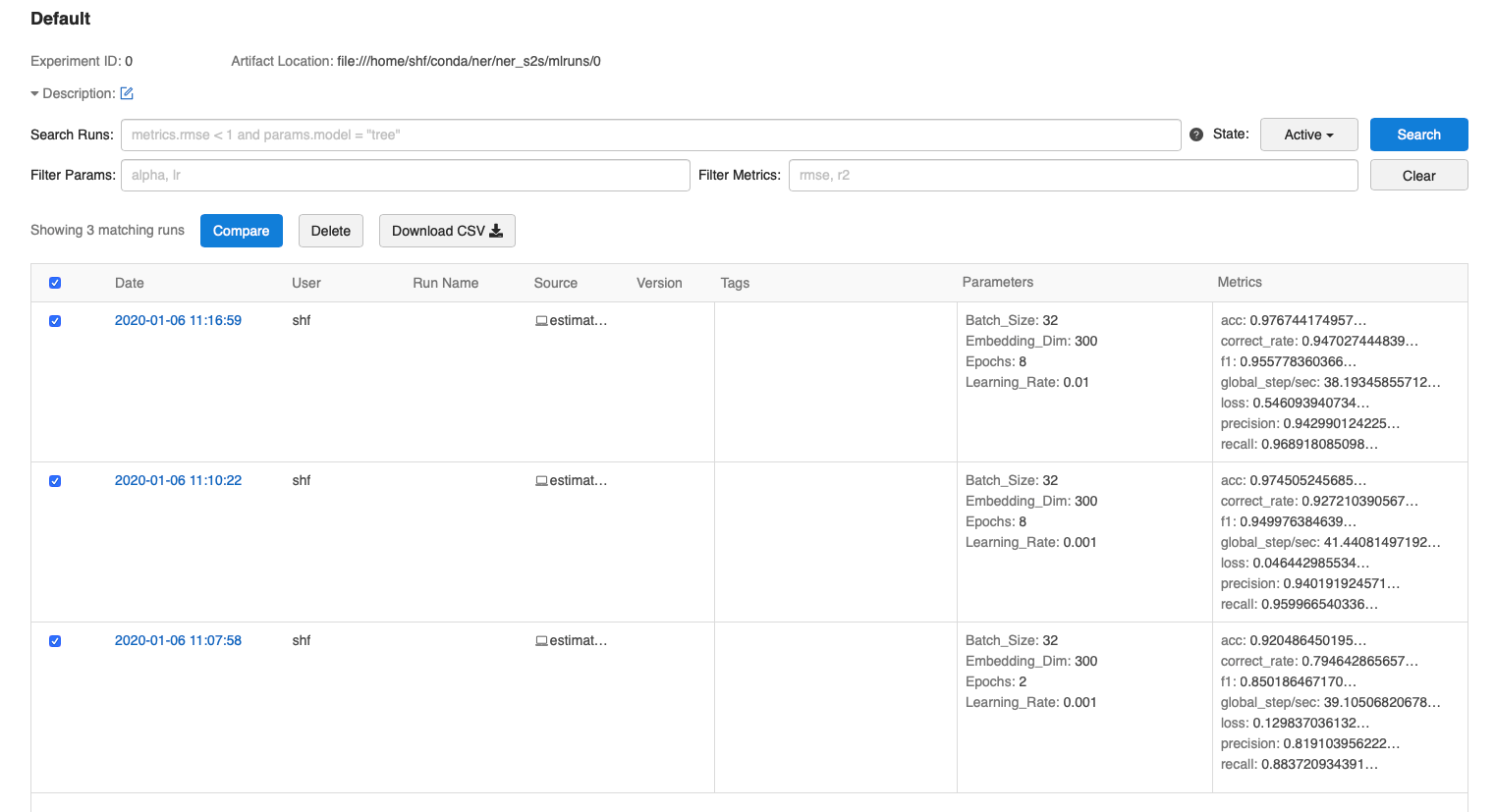
使用 compare 功能 筛选出想要比较的模型参数,可以清晰的看出模型超参数的变化对评价指标的影响
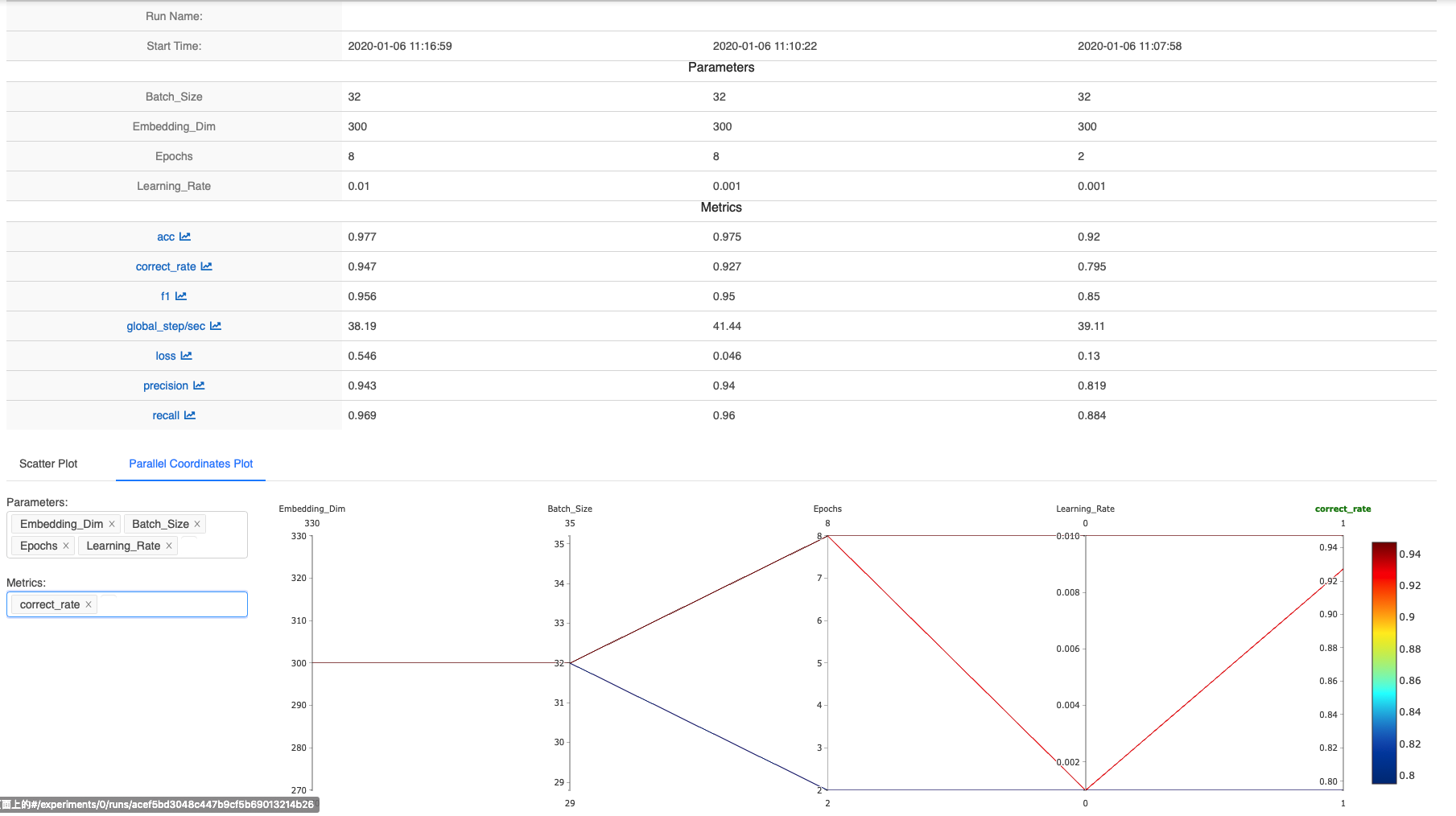
选择具体的模型指标,比如这里的 correct_rare(整句的准确率),比较不同参数下模型指标的变化情况,有点类似tensorboard
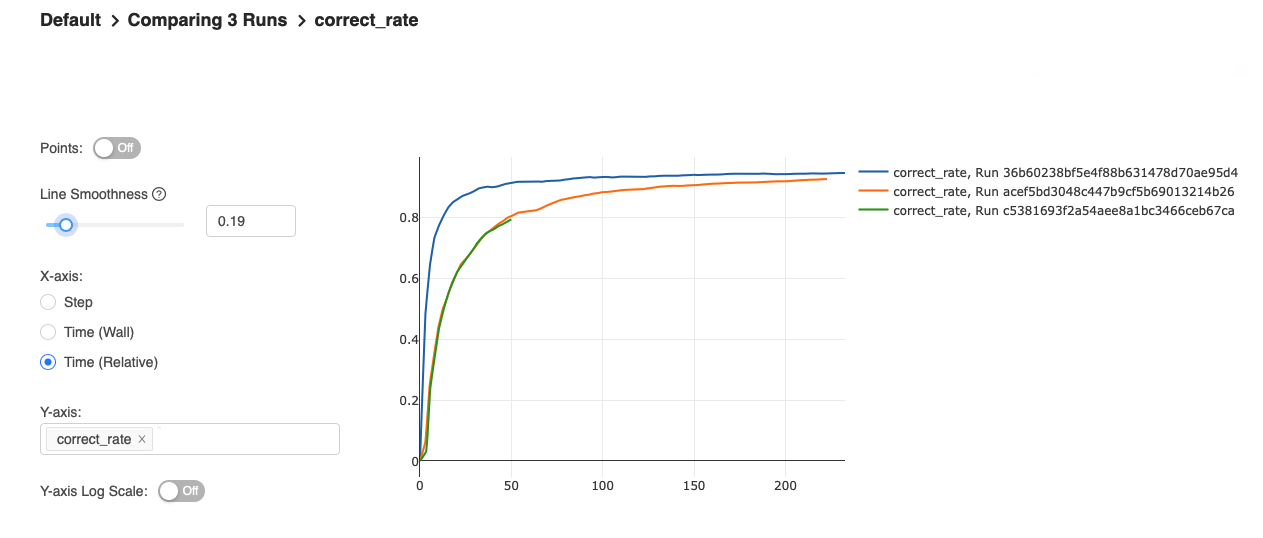
此外 mlflow ui 界面还提供了搜索功能快速筛选出许多模型。需要根据需要去慢慢发掘
Projects
对写好的代码,可以对其进行打包,这样方便其他人来使用该模型,同时自己也可以远程训练模型。
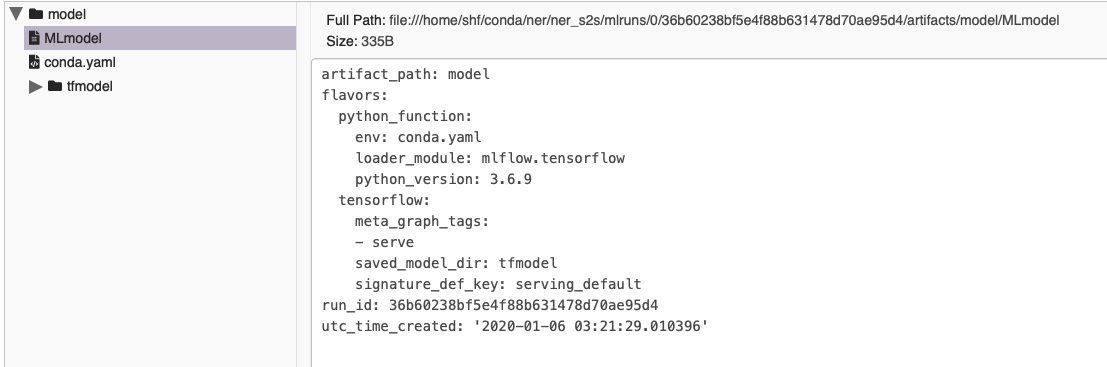
在界面的的 model 目录下,包含 MLmodel 文件和 conda.yaml
MLmodel文件来指定项目的conda依赖与参数的入口文件(可以自己设置)
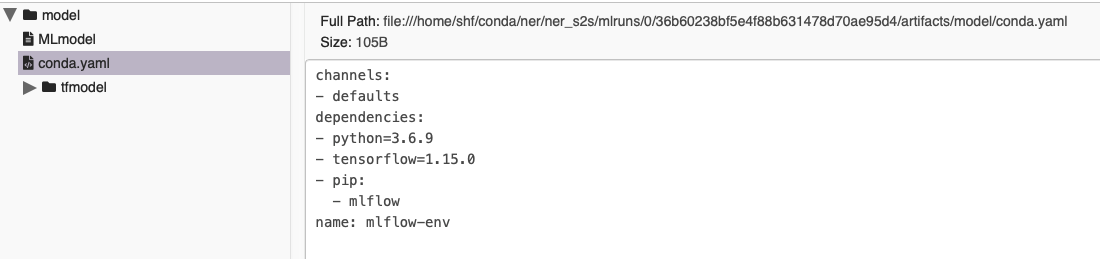
conda.yaml文件列举了所有依赖:
Models
这时已经使用 MLproject 设置好打包模型并确定了最佳模型,比如本文correct_rare(整句的准确率)最高的模型
我们通过MLflow Models来部署模型。 一个 MLflow Model 是一种打包机器学习模型的标准格式,可以被用于多种下游工具,比如实时推理的 REST API或者批量推理的 Apache Spark。
# mlflow Logging the saved model
mlflow.tensorflow.log_model(tf_saved_model_dir=final_saved_model,
tf_meta_graph_tags=[tag_constants.SERVING],
tf_signature_def_key="serving_default",
artifact_path="model")
生成的文件目录的文件夹:
部署服务器
。。。