1.Rasa概述
Rasa是一个开源的基于机器学习的chatbot开发框架
其主要分成两大模块:
- Rasa NLU
- Rasa Core
使用 Rasa NLU + Rasa Core,开发者可以迅速构建自己的chatbot
本文首先介绍基于任务型对话系统(Task-Bot)的主要概念,然后分析了Rasa的结构组成,介绍开发者如何方便地利用Rasa构建自己的chatbot
2.任务型对话系统(Task-Bot)
自然语言理解(NLU)和对话管理是任务型对话的主要模块。自然语言理解是问答系统、聊天机器人等更高级应用的基石。
2.1 典型对话系统
- 检索型问答系统(IR-bot): 主要针对问答系统,提一个问题,给一个答案,不需要参考上下文内容的形式。
- 任务型对话系统(Task-bot): 针对查询业务,订票之类的任务型对话。
- 闲聊系统(Chitchat-bot): 像微软小冰,apple Siri等主要陪聊天等。
2.2 Task-Bot
任务型对话系统示意图:
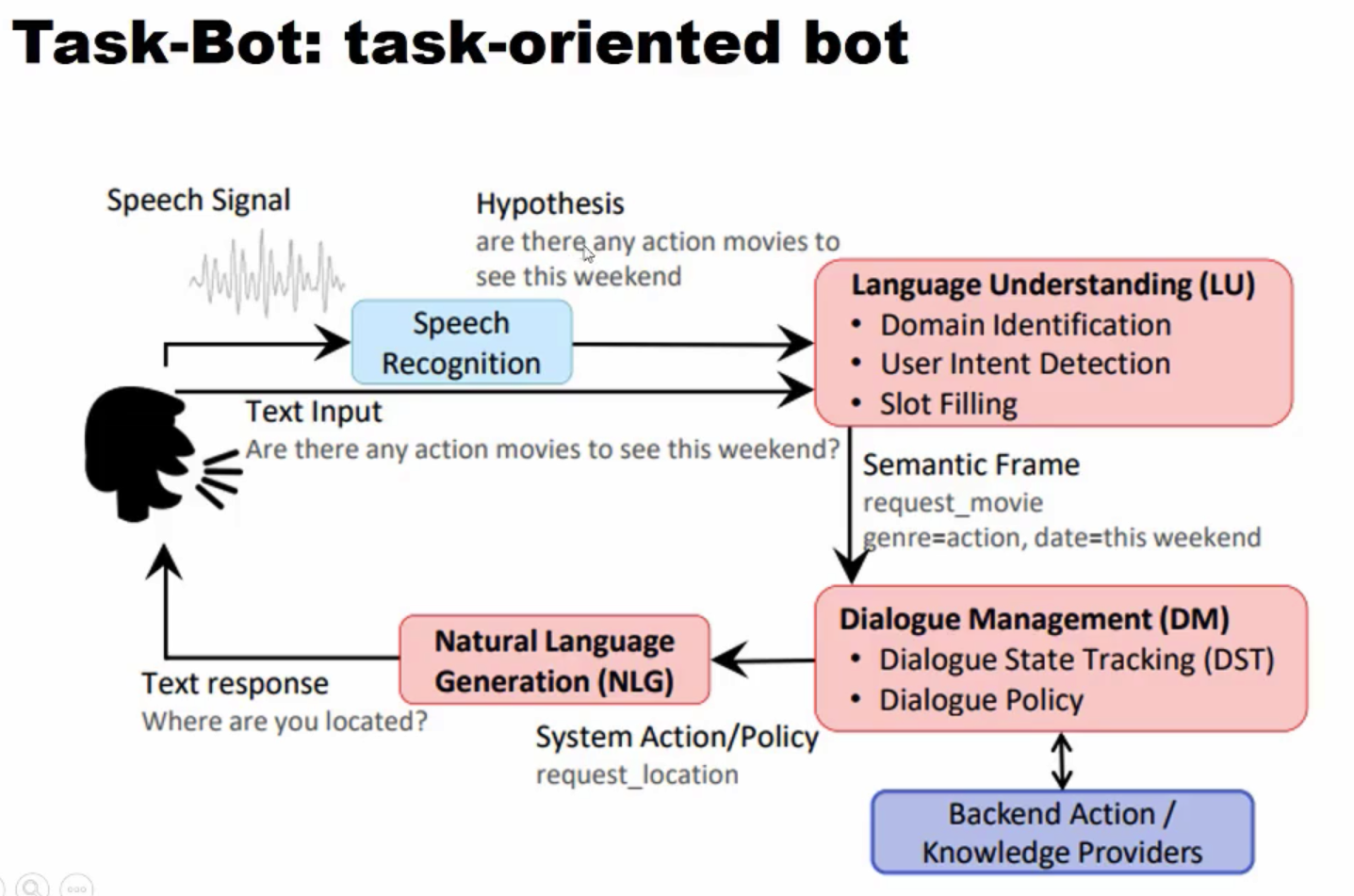
任务型对话主要包括四部分: 语音识别(ASR),自然语言理解(NLU),对话管理(DM),最后是自然语言生成(NLG)。
下面是一个订餐应用的例子:
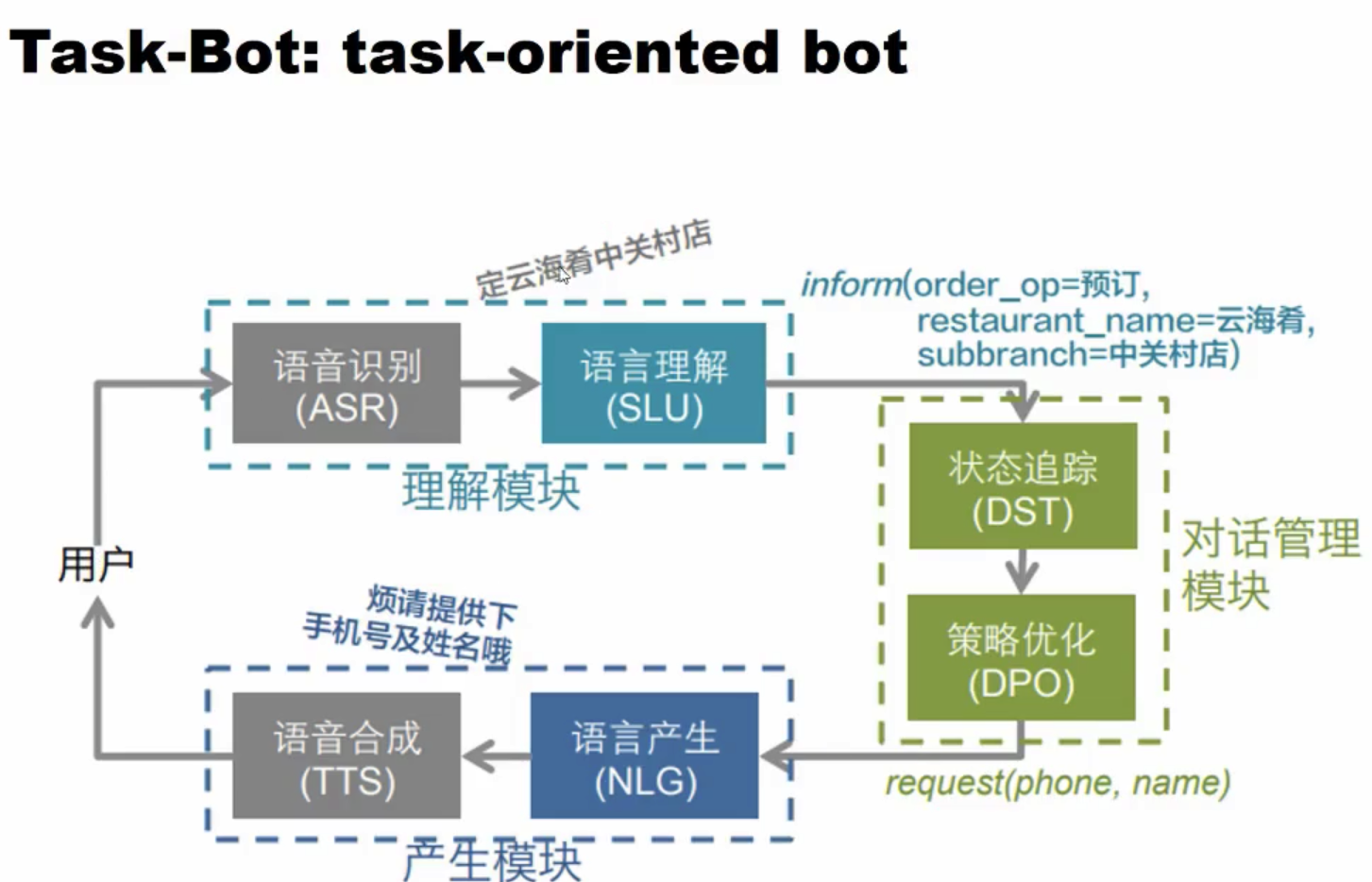
接下来分别来看每个模块具体实现的方式
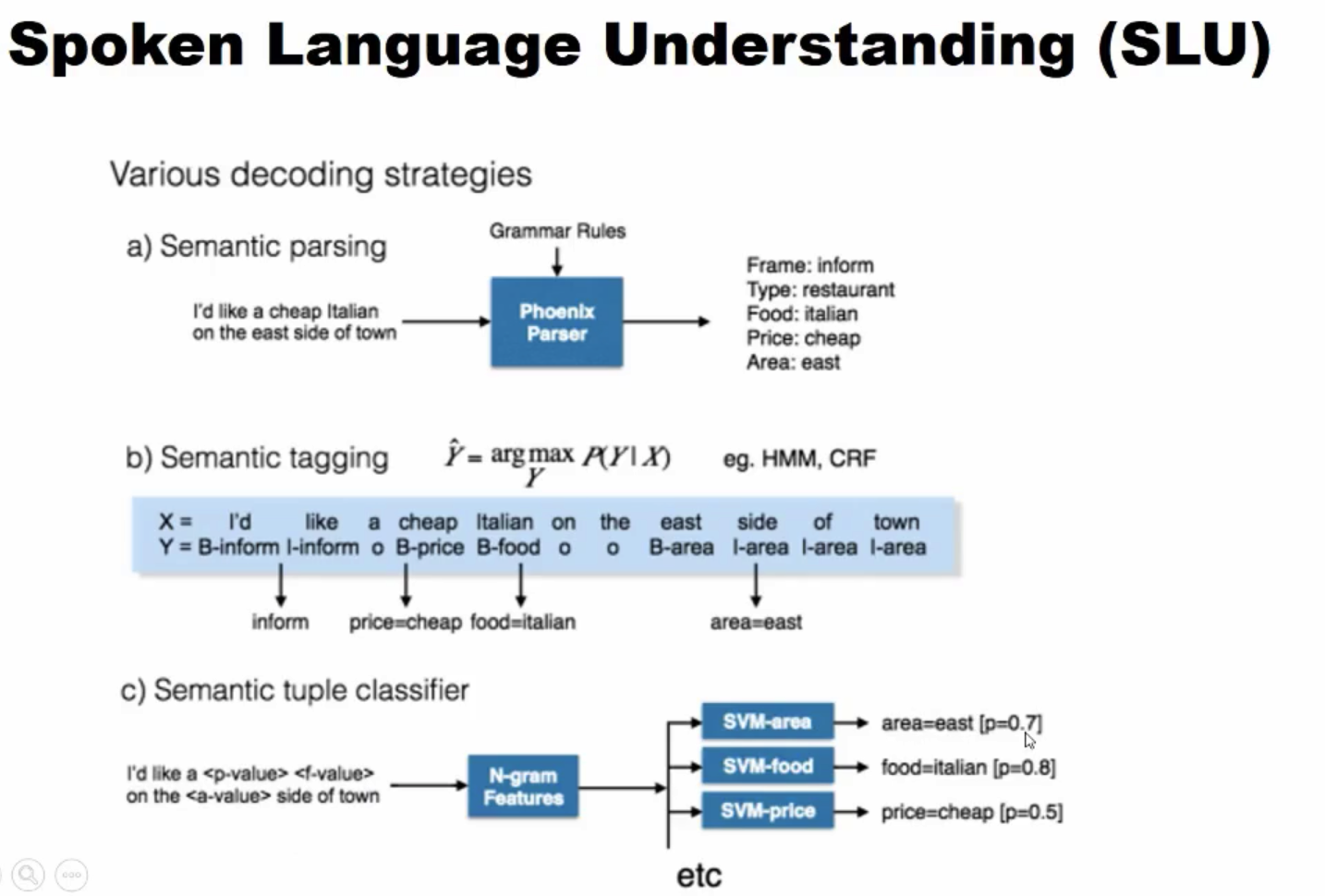
首先是自然语言理解(NLU)。做自然语言理解首先要有一种表示自然语言含义的形式,一般用传统的三元组方式即:
action, slot , value。action就是意图,slot是需要填充的槽值,value是对应的值。

具体可以用哪些技术做这些事情呢?下面列出了几个方法。
- 语法分析,可以通过语法规则去分析一句话,得到这句活是疑问句还是肯定句,继而分析出用户意图。相应的也可以通过语法结构中找到对应的槽值。
- 生成模式,主要两个代表性的HMM,CRF, 这样就需要标注数据。
- 分类思想,先对一句话提取特征,再根据有多少个槽值或意图训练多少个分类器,输入一句话分别给不同的分类器,最终得到包含槽值的概率有多大,最终得到这个槽值。
- 深度学习,使用 LSTM+CRF 两种组合的方式进行实体识别,现在也是首选的方法,但有一个问题是深度学习的速度比较慢,一般轻量型的对话系统还是通过语法分析或分类方式或序列标注来做。
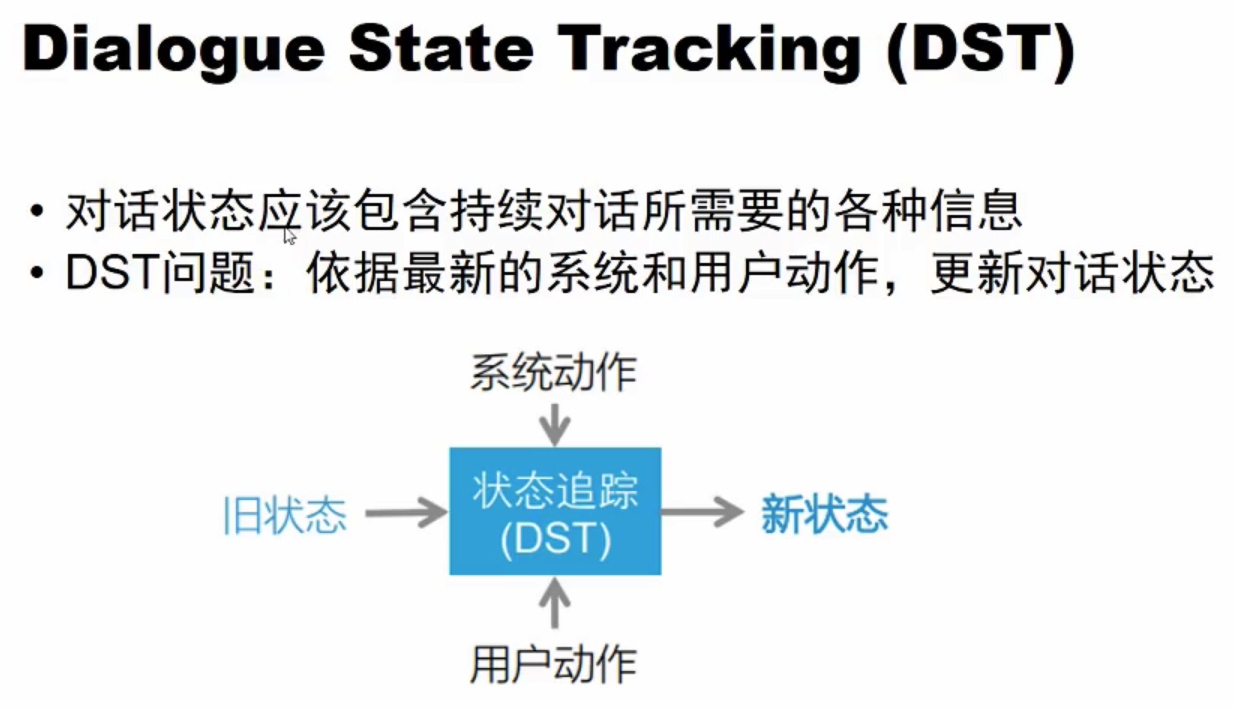
对话状态应该包含持续对话所需要的各种信息。DST的主要作用是记录当前对话状态,作为决策模块的训练数据。
系统如何做出反馈动作?
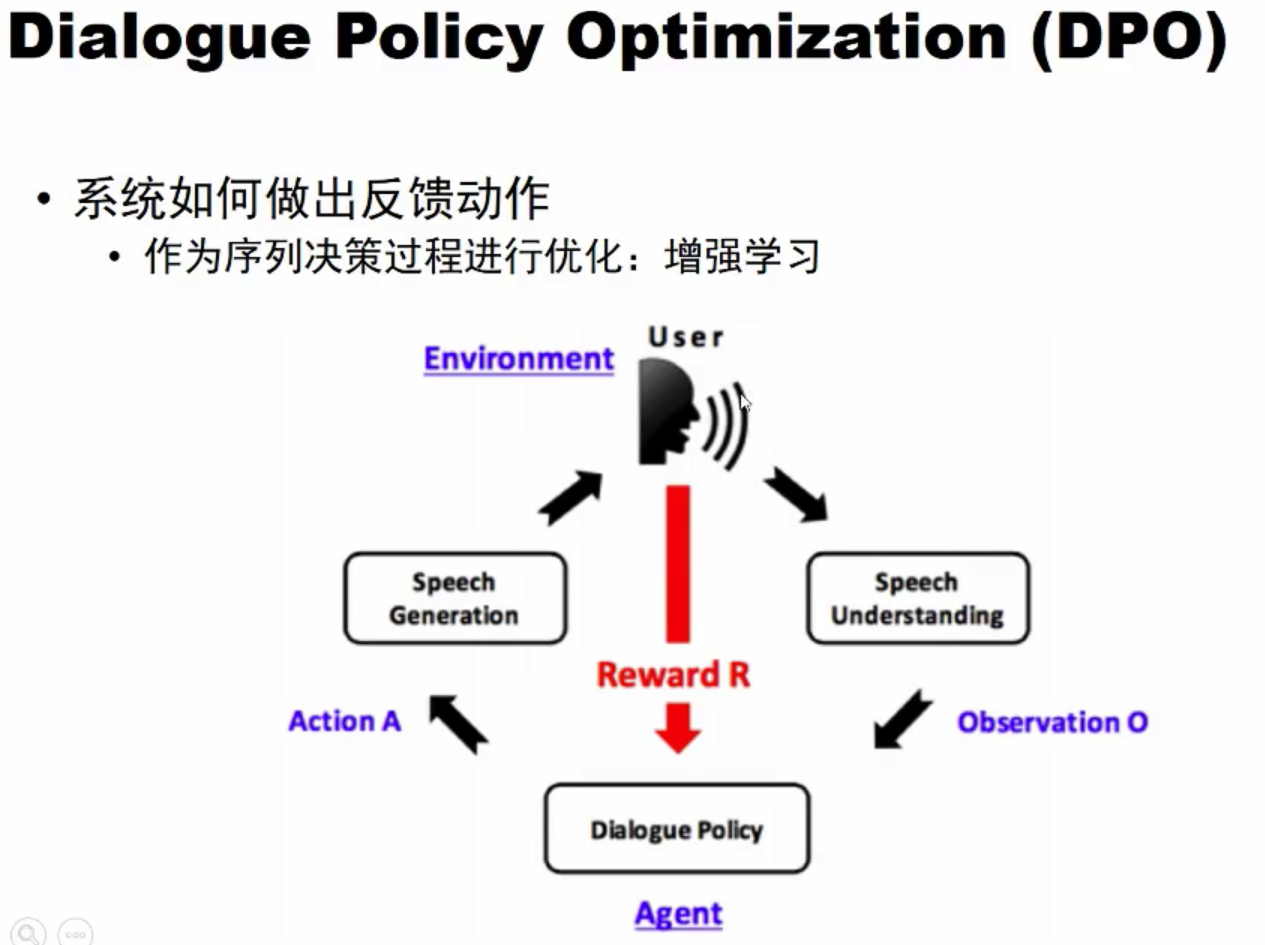
3. Rasa 结构
3.1 Rasa NLU
Rasa NLU负责提供自然语言理解的工具,包括意图分类和实体抽取。
举例来说,对于输入:
帮我找一间市中心的西餐厅
Rasa NLU的输出是:
{
"intent": "search_restaurant",
"entities": {
"cuisine" : "西餐厅",
"location" : "市中心"
}
}
其中,Intent 代表用户意图。Entities 即实体,代表用户输入语句的细节信息。
3.1.1 预定义的pipeline
rasa nlu 支持不同的 Pipeline,其后端实现可支持 spaCy、MITIE、MITIE + sklearn、tensorflow等,其中 spaCy 是官方推荐的。
本文使用的 pipeline 为 MITIE+Jieba+sklearn, rasa nlu 的配置文件为 ivr_chatbot.yml如下:
language: "zh"
project: "ivr_nlu"
fixed_model_name: "demo"
path: "models"
pipeline:
- name: "nlp_mitie"
model: "data/total_word_feature_extractor.dat" // 加载 mitie 模型
- name: "tokenizer_jieba" // 使用 jieba 进行分词
- name: "ner_mitie" // mitie 的命名实体识别
- name: "ner_synonyms" // 同义词替换
- name: "intent_entity_featurizer_regex" //
- name: "intent_featurizer_mitie" // 特征提取
- name: "intent_classifier_sklearn" // sklearn 的意图分类模型
每个组件都可以实现Component基类中的多个方法;在管道中,这些不同的方法将按特定的顺序调用。
假设,添加了以下管道到配置:”pipeline”: [“Component A”, “Component B”, “Last Component”]。
下图为该管道训练时的调用顺序: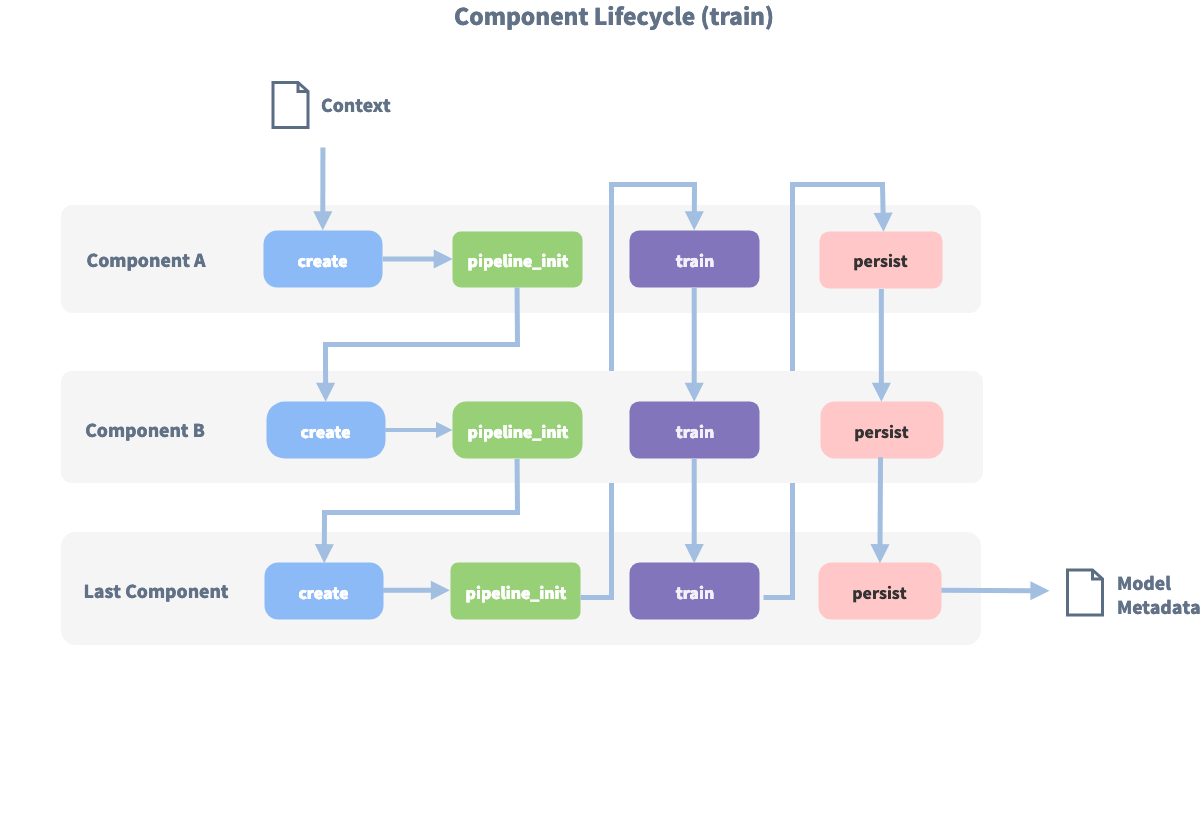
在使用create函数创建第一个组件之前,将创建一个所谓的 context上下文(仅是一个python dict)。此context上下文用于在组件之间传递信息。 例如,一个组件可以计算训练数据的特征向量,将其存储在上下文中,另一个组件可以从context上下文中检索这些特征向量并进行意图分类。
3.1.2 Preparation Work
由于在 pipeline 中使用了 MITIE,所以需要一个训练好的 MITIE 模型。MITIE 模型是非监督训练得到的,类似于 word2vec 中的 word embedding, 需要大量的中文语料,由于训练这个模型对内存要求较高,并且耗时很长,这里直接使用了网友分享的中文 wikipedia 和百度百科语料生成的模型文件 total_word_feature_extractor_chi.dat。
实际应用中,如果做某个特定领域的 NLU 并收集了很多该领域的语料,可以自己去训练 MITIE 模型,也可以用attention,bilstm,bert 来预训练词向量。
3.1.3 构建 rasa_nlu 语料
得到 MITIE 词向量模型以后便可以借助其训练 Rasa NLU 模型,这里需要使用标注好的数据来训练 rasa_nlu,标注的数据格式如下: Rasa 也很贴心的提供了数据标注平台rasa-nlu-trainer 供用户标注数据。这里我们使用项目里提供的标注好的数据(mobile_nlu_data.json)直接进行训练。
# mobile_nlu_data.json
{
"text": "帮我查一下我十二月消费多少",
"intent": "request_search",
"entities": [
{
"start": 9,
"end": 11,
"value": "消费",
"entity": "item"
},
{
"start": 6,
"end": 9,
"value": "十二月",
"entity": "time"
}
]
},
.....
3.1.4 训练 rasa_nlu 模型
python -m rasa_nlu.train --data ./data/mobile_nlu_data.json \
--config ivr_chatbot.yml \
--path projects \
--fixed_model_name demo \
--project ivr_nlu
3.1.5 测试 rasa nlu
$ python httpserver.py
$ curl -X POST localhost:1235/parse -d '{"q":"我的流量还剩多少"}' | python -m json.tool
{
'q': '我的流量还剩多少',
'intent': 'request_search',
'entities': {
'item': '流量'
}
}
3.2 Rasa Core
Rasa 整体框架 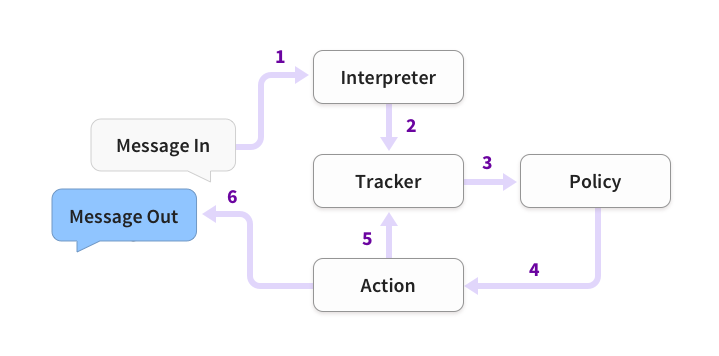
Action
action是对系统响应的抽象。Rasa将对话管理视作一个分类问题,每轮都会在预先设定好的action集合中选出一个类别。Rasa Core定义了3中action:
default action:系统预先定义好的动作,如action_listen、action_restart、action_default_fallbackutter action:一般以utter_开头,这种action就只会单纯地给用户返回文本消息。这类的action无需具体实现代码,只需在配置文件中指定其对应的相应文本模板即可。custom action:用户可以任意编写此类action的代码。用户一般需要自己架设一个额外服务,然后在实现action时,让代码请求这个服务。
Tracker
Tracker是用于追踪对话状态的模块。当用户输入被解析后,会传入Tracker进行更新,然后系统会读取Tracker里的信息,作为策略判断的输入。
目前支持的tracker:
- InMemoryTrackerStore (default)
- RedisTrackerStore
- MongoTrackerStore
- Custom Tracker Store
Events
Events用于描述一个对话过程中任何可能发生的事情。
Dispatcher
Dispatcher的作用是将消息以各种形式发送给用户。
Action + Dispatcher + Tracker + Events:
当action被执行的时候,通常会将一个tracker对象传进去。这样它就可以利用各种相关的信息,比如slots、之前的utterance还有之前的action。
action被执行的时候,通常会调用dispatcher将消息返还给用户。执行过程本身并不直接修改tracker,但是执行的完成后可能会返回events,tracker可以消费这些event,并更新状态。
Policy
policy的输入是tracker记录的当前对话状态,输出是一个系统响应action。
policy包含一个featurizer。一个featurizer可以创造一个代表当前对话状态的向量。
特征包括以下三部分:
- 1.上轮动作
- 2.上轮的intent和entities
- 3.本轮的slots
一个很重要的超参max_history:指定了要考虑多少个之前的状态。通常取值为 3-6 。
Story
所谓的story有点像剧本,描述可能出现的对话场景。实际上story就是一个个用户输入intent(entities)和系统设定的输出action用于policy的训练。
格式:
## story名称
* 用户的intent或者entity
- 系统的action
etc:
## interactive_story_4
## 天气/时间 + 地点 + 时间
* request_weather{"date_time": "明天"}
- weather_form
- form{"name": "weather_form"}
- slot{"date_time": "明天"}
- slot{"requested_slot": "address"}
* form: inform{"address": "广州"}
- form: weather_form
- slot{"address": "广州"}
- form{"name": null}
- slot{"requested_slot": null}
* inform{"date_time": "后天"} OR request_weather{"date_time": "后天"}
- weather_form
- form{"name": "weather_form"}
- slot{"date_time": "明天"}
- slot{"address": "广州"}
- slot{"date_time": "后天"}
- form{"name": null}
- slot{"requested_slot": null}
* thanks
- utter_answer_thanks
Domain
domain可以理解为机器的知识库,其中定义了意图,动作,以及对应动作所反馈的内容。
| 标识 | 说明 |
|---|---|
| intents | 意图 |
| actions | 动作 |
| templates | 回答模板 |
| entities | 实体 |
| slots | 词槽 |
etc:domain.yml
slots:
time:
type: text
phone_number:
type: text
price:
type: text
...
intents:
- greet
- request_search
- deny
- inform_other_phone
...
entities:
- item
- time
- phone_number
- price
...
templates:
utter_greet:
- "您好!,我是机器人小热,很高兴为您服务。"
- "你好!,我是小热,可以帮您办理流量套餐,话费查询等业务。"
- "hi!,人家是小热,有什么可以帮您吗。"
utter_default:
- "您说什么"
- "您能再说一遍吗,我没听清"
utter_thanks:
- "不用谢"
- "我应该做的"
- "您开心我就开心"
utter_ask_time:
- "你想查哪个时间段的"
- "你想查几月份的"
utter_ask_package:
- "我们现在支持办理流量套餐:套餐一:二十元包月三十兆;套餐二:四十元包月八十兆,请问您需要哪个?"
- "我们有如下套餐供您选择:套餐一:二十元包月三十兆;套餐二:四十元包月八十兆,请问您需要哪个?"
utter_ack_management:
- "已经为您办理好了{item}"
...
actions:
- utter_greet
- utter_default
- utter_thanks
- utter_ask_time
- utter_ask_package
- bot.ActionSearchConsume
...
Rasa Core的任务是在获取到用户的意图后,选择正确的action,这些action就是定义在domain中以utter_开头的内容,
每一个action会根据templates中的情况来返回对应的内容。
train dialogue
# python bot.py train-dialogue
def train_dialogue(domain_file="mobile_domain.yml",
model_path="projects/dialogue",
training_data_file="data/mobile_story.md"):
agent = Agent(domain_file,
policies=[MemoizationPolicy(), KerasPolicy()])
training_data = agent.load_data(training_data_file)
agent.train(
training_data,
epochs=200,
batch_size=16,
augmentation_factor=50,
validation_split=0.2
)
agent.persist(model_path)
return agent
执行上面的脚本 训练对话模型,训练的模型将会存储在projects/dialogue文件夹下
train dialogue in online mode
交互式,让用户在每一次机器做出决定之后,给与反馈。
原理:每次系统给出动作的时候,收集用户的 y/n 的信息,生成新的训练数据保存在story中,对模型fine-tune。
# python bot.py online_train
def run_ivrbot_online(input_channel=ConsoleInputChannel(),
interpreter=RasaNLUInterpreter("projects/ivr_nlu/demo"),
domain_file="mobile_domain.yml",
training_data_file="data/mobile_story.md"):
agent = Agent(domain_file,
policies=[MemoizationPolicy(), KerasPolicy()],
interpreter=interpreter)
training_data = agent.load_data(training_data_file)
agent.train_online(training_data,
input_channel=input_channel,
batch_size=16,
epochs=200,
max_training_samples=300)
return agent
test
Run command below:
python bot.py run
Example1:
Bot loaded. Type a message and press enter :
YOU:你是谁
BOT:您好!,我是机器人小热,很高兴为您服务。
YOU:我想看一下消费情况
BOT:你想查哪个时间段的
YOU:上个月的
BOT:好,请稍等
BOT:您好,您上个月共消费二十八元。
BOT:还有什么能帮您吗
YOU:没啥了
BOT:Bye, 下次再见
Example2:
Bot loaded. Type a message and press enter :
BOT:你好!,我是小热,可以帮您办理流量套餐,话费查询等业务。
YOU:有什么套餐
BOT:我们现在支持办理流量套餐:套餐一:二十元包月三十兆;套餐二:四十元包月八十兆,请问您需要哪个?
YOU:套餐一
BOT:已经为您办理好了套餐一
BOT:您还想干什么
YOU:没有
BOT:再见,为您服务很开心